详谈大模型训练和推理优化技术 |
您所在的位置:网站首页 › 系统优化的因素 通用技术 › 详谈大模型训练和推理优化技术 |
详谈大模型训练和推理优化技术
|
详谈大模型训练和推理优化技术
作者:王嘉宁,转载请注明出处:https://wjn1996.blog.csdn.net/article/details/130764843 ChatGPT于2022年12月初发布,震惊轰动了全世界,发布后的这段时间里,一系列国内外的大模型训练开源项目接踵而至,例如Alpaca、BOOLM、LLaMA、ChatGLM、DeepSpeedChat、ColossalChat等。不论是学术界还是工业界,都有训练大模型来优化下游任务的需求。 然而,大量实验证明,在高质量的训练语料进行指令微调(Instruction-tuning)的前提下,超过百亿参数量的模型才具备一定的涌现能力,尤其是在一些复杂的推理任务上,例如下图: 图来自论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》 也就是说,如果我们需要通过大模型技术来提升业务指标,不得不要求我们去训练一个百亿规模的模型。 然而,一般情况下,我们不具备如此大规模的计算资源,尤其是对于学校里一般的科研团队,也许只有少量V100(32G),运气好可能会有几台A100。因此在有限的算力条件下训练或推理一个百亿量级的大模型是不太现实的。因此,无疑要在训练和推理两个阶段采用一些优化策略来解决此类问题。 本篇博文主要整理一系列大模型在训练和推理两个阶段的优化技术,以满足我们在有限的计算资源的条件下训练自己的大模型,下面列出本文主要介绍的一些优化技术: 混合精度训练:FP16+FP32 或 BF16+FP32;DeepSpeed分布式训练:ZeRO-1、ZeRO-2、ZeRO-3;Torch FSDP + CPU Offloading;3D并行;INT8模型量化:对称/非对称量化、量化感知训练;参数有效性学习(Parameter-Efficient Learning):LoRA、Adapter、BitFit、P-tuning;混合专家训练(Mixed-of Experts,MoE):每次只对部分参数进行训练;梯度累积(Gradient Accumulation):时间换空间梯度检查点(Gradient checkpointing):时间换空间Flash Attention 一、Transformer模型算力评估在介绍优化技术之前,首先介绍一下如何评估大模型的算力。众所周知,现如今的预训练语言模型均是基于Transformer结构实现的,因此大模型的参数主要来源于Transformer的Self-Attention部分。EleutherAI团队近期发布一篇博客来介绍如何估计一个大模型的算力成本,公式如下: C = τ T ≈ 6 P D C=\tau T\approx 6PD C=τT≈6PD 其中: C C C 表示Transformer需要的计算量,单位是FLOP; P P P 表示Transformer模型包含的参数量; D D D 表示训练数据规模,以Token数量为单位; τ \tau τ 表示吞吐量,单位为FLOP T T T 表示训练时间; 该公式的原理如下: C = C forward + C backward C=C_{\text{forward}}+C_{\text{backward}} C=Cforward+Cbackward:表示训练过程中的前后向传播; C forward ≈ 2 P D C_{\text{forward}}\approx2PD Cforward≈2PD:前向传播计算成本约等于两倍的参数量乘以数据规模; C backward ≈ 4 P D C_{\text{backward}}\approx4PD Cbackward≈4PD:反向传播计算成本约等于四倍的参数量乘以数据规模; C C C 是一个量化计算成本的单位,通常用FLOP表示,我们也可以用一些新的单位来表示: FLOP/s-s:表示每秒浮点运算数 × \times ×秒;PetaFLOP/s-days:表示实际情况下每秒浮点运算数 × \times ×天。下图展示了不同规模的预训练语言模型的算力成本: 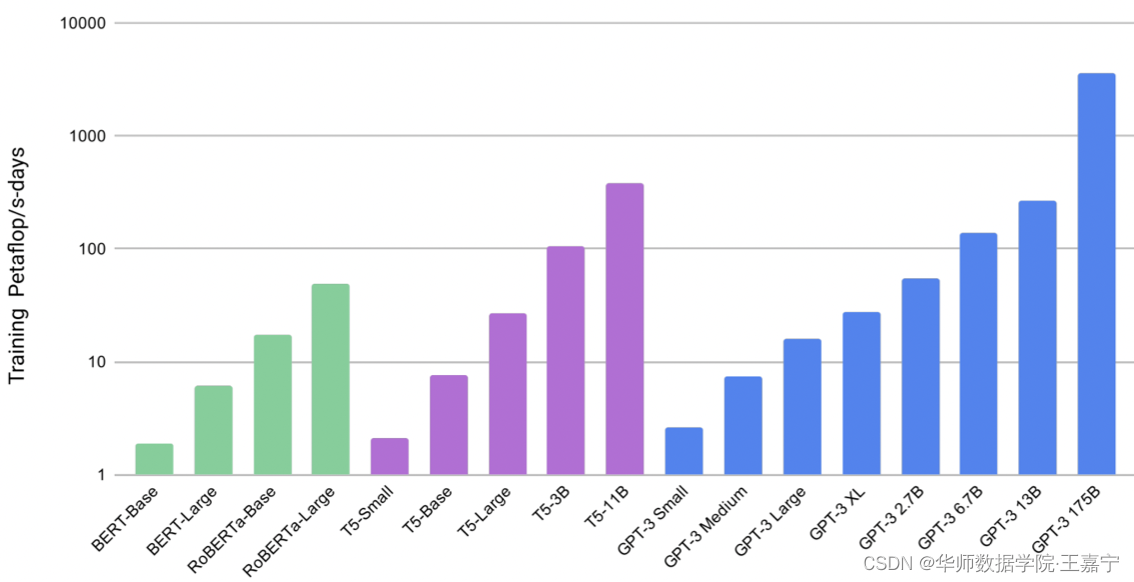
可知,随着规模的增大,其算力成本会呈现指数级别的增长。 参见原文:https://blog.eleuther.ai/transformer-math/ 二、混合精度训练混合精度训练是一个很常用的显存优化技术,其适用于单机单卡或多卡并行场景。 一般情况下,计算机在进行浮点运算时所采用的是FP32(单精度),其中8位用于存储整数部分,23位存储小数部分,因此其可以存储高精度浮点数。 因此在显存优化场景下,牺牲浮点运算的精度可以降低存储量。例如采用FP16进行浮点运算时,只需要一半的存储空间即可,因此成为半精度浮点运算。但是FP16的整数为只能最大到65536,很容易出现溢出问题,为此,BF16是另一种半精度浮点运算表示,其相较于FP16来说,增大了整数部分的存储位,避免计算溢出问题,但是也牺牲了一定的精度。 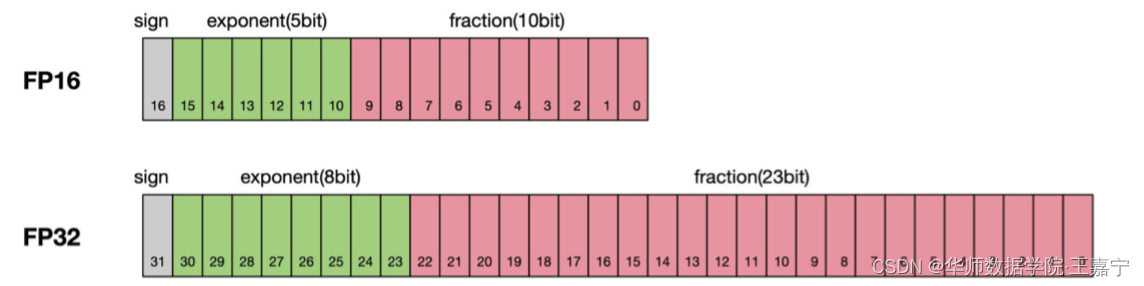
在实际的训练时,通常是将单精度与半精度进行混合实现浮点运算的。典型代表是动态混合精度法(Automatic Mixed Precision,AMP),如下图所示: 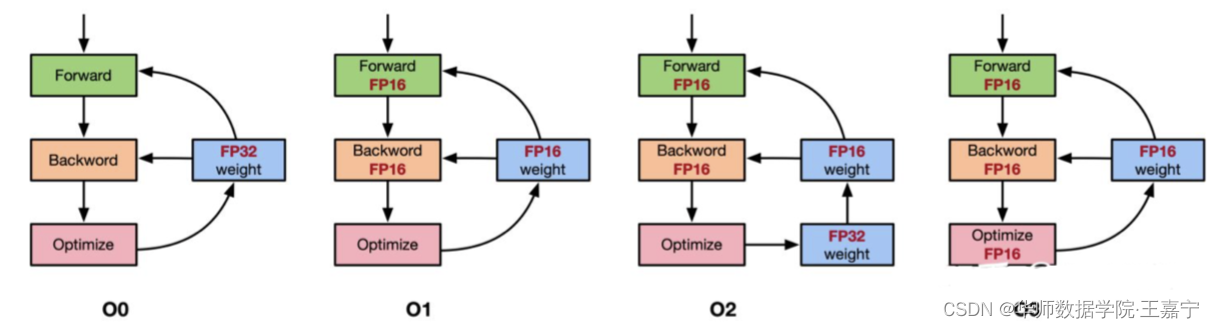 O0:表示最原始的FP32浮点运算;O1:除了优化器部分为FP32,其余都使用FP16;O2:在O1的基础上,额外使用FP32保存了一份参数用于参数更新;O3:所有参数全部为半精度;
O0:表示最原始的FP32浮点运算;O1:除了优化器部分为FP32,其余都使用FP16;O2:在O1的基础上,额外使用FP32保存了一份参数用于参数更新;O3:所有参数全部为半精度;
AMP采用的是混合FP32+FP16,在不同的训练阶段动态地指定那些部分转换为半精度进行训练。AMP典型的是使用上图的O2部分,即使用混合精度训练不仅可以提高乘法运算过程中的效率问题,还有效避免累加时的舍入误差问题。 Pytorch1.5版本后继承了AMP的实现,调用AMP进行混合精度训练的例子如下: from torch.cuda.amp import autocast, GradScaler # FP32模型 model = Net().cuda() optimizer = optim.SGD(model.parameters(), ...) scaler = GradScaler() for epoch in epoches: for input, target in data: optimizer.zero_grad() with autocast(): output = model(input) loss = loss_fn(output, target) scaler.scale(loss).backward() scaler.step(optimizer) scale.update() 三、DeepSpeed分布式训练一张32G的GPU上可能无法塞得下100亿模型的权重、梯度、优化器等参数,但是我们或许可以将这些参数按照一定规则拆分到多张卡上,这便是分布式并行优化的思想。 DeepSpeed是由微软开源的分布式训练加速框架,其使用了一种称为零冗余(ZeRO)的显存优化技术。本质上,它是一种数据并行的分布式训练策略,重点优化了数据并行中的显存占用问题。在ZeRO数据并行中,每个GPU上虽然拥有完整的网络,但是每个GPU只保存一部分的权重,梯度和优化器状态信息,这样就就可以将权重,梯度,优化器状态信息平均分配到多个GPU上。 下图展示了DeepSpeed的3种ZeRO stage。假设需要训练的模型占用显存位120G,集群内有 N d = 64 N_d=64 Nd=64张GPU: 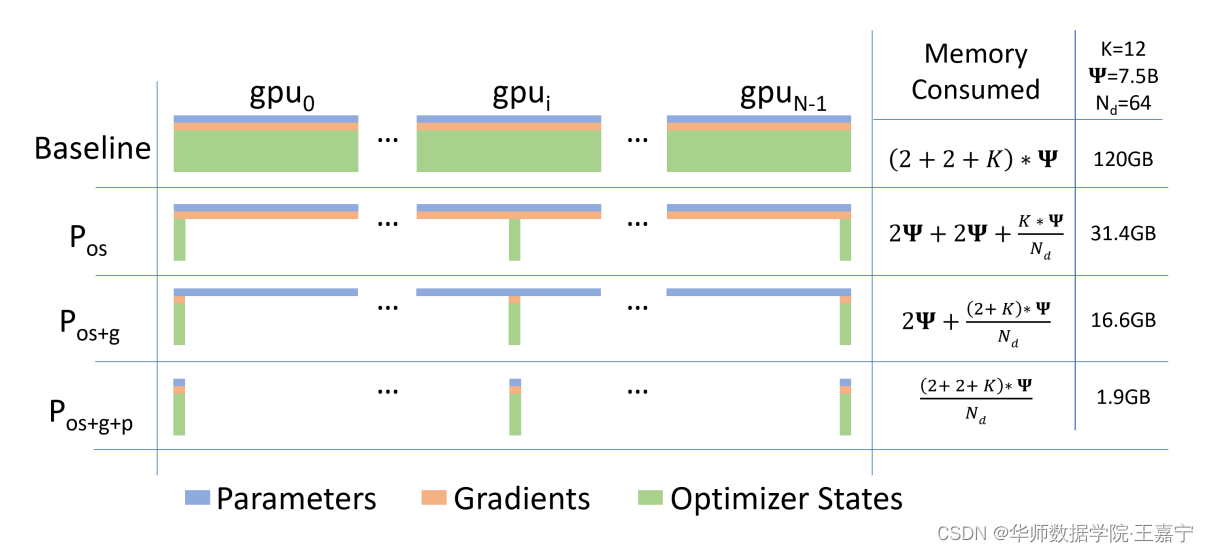 Baseline:传统的数据并行策略,每张GPU上存储全部模型的权重、梯度和优化器等参数,每张卡上并行训练不同的数据,并实现参数汇聚更新。该情况下,每张卡依然要加载120G参数,显然是无法在一般机器上实现的;ZeRO Stage1——优化器并行:在训练过程中,优化器状态参数占用的显存空间是非常大的,因此将优化器状态参数分发到不同的GPU上,此时单张卡上的显存占用会大大降低;ZeRO Stage2——梯度+优化器并行:在ZeRO Stage1的基础上,额外对梯度进行了分布式存储,可以发现120G的显存占用直接降低到16G;ZeRO Stage3——权重+梯度+优化器并行:模型的所有参数都进行分布式存储,此时一张卡上只有1.9G占用。
Baseline:传统的数据并行策略,每张GPU上存储全部模型的权重、梯度和优化器等参数,每张卡上并行训练不同的数据,并实现参数汇聚更新。该情况下,每张卡依然要加载120G参数,显然是无法在一般机器上实现的;ZeRO Stage1——优化器并行:在训练过程中,优化器状态参数占用的显存空间是非常大的,因此将优化器状态参数分发到不同的GPU上,此时单张卡上的显存占用会大大降低;ZeRO Stage2——梯度+优化器并行:在ZeRO Stage1的基础上,额外对梯度进行了分布式存储,可以发现120G的显存占用直接降低到16G;ZeRO Stage3——权重+梯度+优化器并行:模型的所有参数都进行分布式存储,此时一张卡上只有1.9G占用。
基于ZeRO在训练过程中的原理,有博主分享比较精妙的图,来源于[多图,秒懂]如何训练一个“万亿大模型”?。假设有2张卡,训练一个2层的Transformer模型: (1)传统的数据并行: 每张卡上都完整的存放模型全部参数(橘黄色部分),包括权重、梯度和优化器。在前向传播过程中,每张卡上独立地对喂入的数据进行计算,逐层获得激活值(Transformer模型中的FeedForward模块的输出): 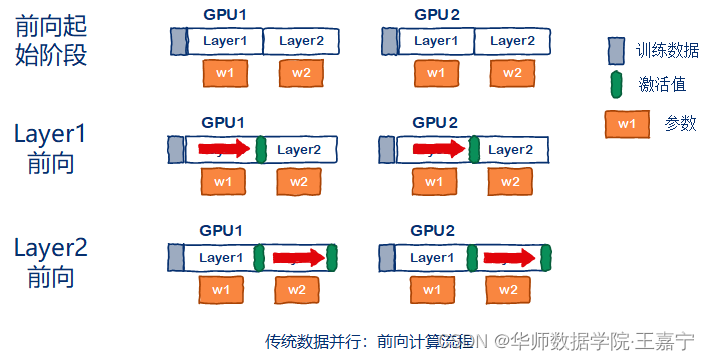 计算梯度时,每个卡上的模型,每个参数都单独计算梯度,并存储下来(紫色部分):
计算梯度时,每个卡上的模型,每个参数都单独计算梯度,并存储下来(紫色部分):
 在梯度更新阶段,对所有卡上的梯度进行平均处理,然后各张卡独立地进行梯度更新,并保存当前的优化器状态信息(浅蓝色部分):
在梯度更新阶段,对所有卡上的梯度进行平均处理,然后各张卡独立地进行梯度更新,并保存当前的优化器状态信息(浅蓝色部分):
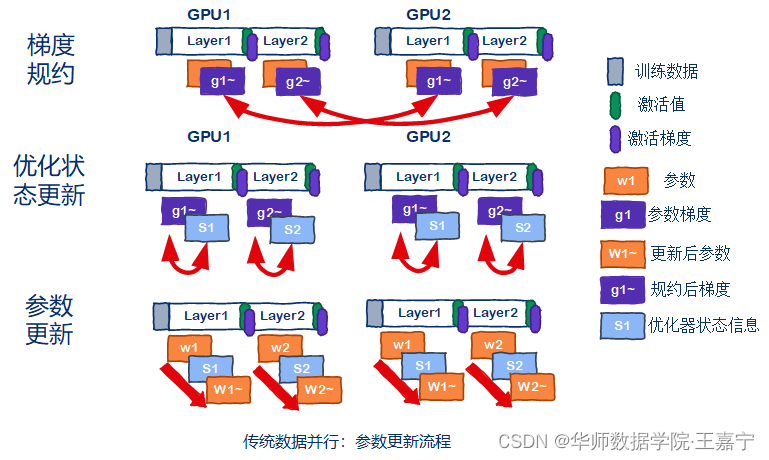
(2)DeepSpeed ZeRO并行训练: DeepSpeed则是在数据并行的基础上,对权重、梯度和优化器状态也进行了分布式存储,下面几张图展示ZeRO Stage3的情况。在初始时,假设两张卡分别只存储一层Transformer。当某一张卡在进行前向传播时,如果此时参数不存在,则需要朝有该参数的卡上借用该参数进行前向计算。例如在GPU1上计算第2层Transformer时,需要GPU2上的参数拷贝给GPU1实现第2层Transformer的计算。 这也是为什么在使用ZeRO的时候,GPU的显存会不断变化。  前向传播结束后,需要进行梯度计算。例如GPU2需要保存w2对应的梯度g2,因此所有其他GPU将g2梯度发送给GPU2。GPU2上面得到各个GPU的g2梯度后,做规约操作并保存,得到g2~。其他GPU将会删除w2,g2。然后重复该流程,直到所有layer都完成反向传播计算:
前向传播结束后,需要进行梯度计算。例如GPU2需要保存w2对应的梯度g2,因此所有其他GPU将g2梯度发送给GPU2。GPU2上面得到各个GPU的g2梯度后,做规约操作并保存,得到g2~。其他GPU将会删除w2,g2。然后重复该流程,直到所有layer都完成反向传播计算:
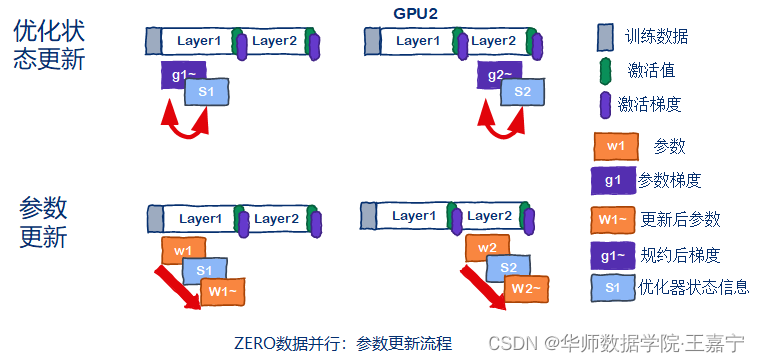
 参数更新时,直接单独进行更新即可:
参数更新时,直接单独进行更新即可:
目前HuggingFace的Transformers库已经集成了DeepSpeed框架,只需要配置ZeRO文件即可,下面列出博主常用的一些配置: (1)ZeRO Stage1: { "train_micro_batch_size_per_gpu": "auto", "zero_optimization": { "stage": 1, "cpu_offload": false }, "fp16": { "enabled": "auto" }, "steps_per_print": 1000 }(2)ZeRO Stage2: { "train_micro_batch_size_per_gpu": "auto", "zero_optimization": { "stage": 2 }, "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "steps_per_print": 1000, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } } }(3)ZeRO Stage3: { "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "bf16": { "enabled": "auto" }, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false }基于HuggingFace的Transformer库在使用时,可直接指定配置文件即可,例如: –deepspeed=./ds_config_fp16_z1.json \ 四、Torch FSDP + CPU OffloadingFully Sharded Data Paralle(FSDP)和 DeepSpeed 类似,均通过 ZeRO 等分布优化算法,减少内存的占用量。其将模型参数,梯度和优化器状态分布至多个 GPU 上,而非像传统的分布式训练在每个GPU上保留完整副本。 CPU offload 则允许在一个 back propagation 中,将参数动态地在GPU和CPU之间相互转移,从而节省GPU显存。 Huggingface 这篇博文解释了 ZeRO 的大致实现方法:https://huggingface.co/blog/zero-deepspeed-fairscale 借助 torch 实现 FSDP,只需要将 model 用 FSDPwarp 一下;同样,cpu_offload 也只需要一行代码:https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/ 在这个可以查看 FSDP 支持的模型:https://pytorch.org/docs/stable/fsdp.html 在 Huggingface Transformers 中使用 Torch FSDP:https://huggingface.co/docs/transformers/v4.27.2/en/main_classes/trainer#transformers.Trainin 五、3D并行上述降到的DeepSpeed、FSDP等都是数据并行,事实上也有模型并行以及流水线并行。关于3D并行的方法可参考文献:https://zhuanlan.zhihu.com/p/617087561 六、INT8量化深度学习模型量化是一个面向模型参数的显存优化技术,其与FP16比较类似,都是为了损失一些精度来降低空间。但不同于FP16的是,INT8量化是一种间接的精度转换方法。在介绍INT8量化之前,需要引入一些基本概念: 定点数:常用的定点数有两种表示形式:如果小数点位置约定在最低数值位的后面,则该数只能是定点整数;如果小数点位置约定在最高数值位的前面,则该数只能是定点小数。浮点数:在存储时,一个浮点数所占用的存储空间被划分为两部分,分别存放尾数和阶码。尾数部分通常使用定点小数方式,阶码则采用定点整数方式。尾数的长度影响该数的精度,而阶码则决定该数的表示范围。为了节省内存,计算机中数值型数据的小数点的位置是隐含的,且小数点的位置既可以是固定的,也可以是变化的。 如果小数点的位置事先已有约定,不再改变,此类数称为“定点数”。相比之下,如果小数点的位置可变,则称为“浮点数”。 > 对称量化(Scale Quantization)这里我们用 r r r表示浮点实数,以及最大最小值 r m a x , r m i n r_{max}, r_{min} rmax,rmin, q q q 表示量化后的定点整数,其最大最小值为 q m a x , q m i n q_{max}, q_{min} qmax,qmin(在INT8中,最大最小值为-128, 127), S S S表示量化因子(scale),即由浮点数到整型数的比例, Z Z Z表示浮点数中0对应量化后的整型数。 当 r m a x = r m i n = α r_{max}=r_{min}=\alpha rmax=rmin=α时,则为对称量化,此时则有: S = 2 a q m a x − q m i n S=\frac{2a}{q_{max} - q_{min}} S=qmax−qmin2a 因为是对称量化,所以浮点数0对应的定点整型数也是0,即: Z = 0 Z=0 Z=0 则对于浮点数 r r r,其量化后的结果是 q = r o u n d ( r S ) q=round(\frac{r}{S}) q=round(Sr); 对于一个整型数,其反量化后的结果是 r = S q r=Sq r=Sq。 对称量化的优缺点: 优势:推理速度快,量化方式简单;缺点:对于一些特殊的值(例如激活函数后的值),往往均大于0,此时会浪费掉INT8的一些空间,使得量化后的结果不均匀。 > 非对称量化(Affine Quantization)这里我们用 r r r表示浮点实数,以及最大最小值 r m a x , r m i n r_{max}, r_{min} rmax,rmin, q q q 表示量化后的定点整数,其最大最小值为 q m a x , q m i n q_{max}, q_{min} qmax,qmin(在INT8中,最大最小值为-128, 127), S S S表示量化因子(scale),即由浮点数到整型数的比例, Z Z Z表示浮点数中0对应量化后的整型数。因此有: S = r m a x − r m i n q m a x − q m i n S=\frac{r_{max} - r_{min}}{q_{max} - q_{min}} S=qmax−qminrmax−rmin Z = r o u n d ( q m a x − r m a x S ) Z=round(q_{max} - \frac{r_{max}}{S}) Z=round(qmax−Srmax) 对于浮点数 r r r,其量化后的结果是 q = r o u n d ( r S + Z ) q=round(\frac{r}{S} + Z) q=round(Sr+Z); 对于一个整型数,其反量化后的结果是 r = S ( q − Z ) r=S(q-Z) r=S(q−Z)。 量化过程中,由于存在round算子,因此会造成精度损失,但是反量化不会造成精度损失; 浮点数0不存在精度损失。 (1)Absmax Quantization(最大量化) 该方法的一个典型的是absmax quantization技术。将一个FP32(单精度4字节)的float类型数据转换为INT8。由于INT8只有-127~127,因此可以通过对FP32值乘以一个量化因子,将浮点数转换为整型数。如下所示: 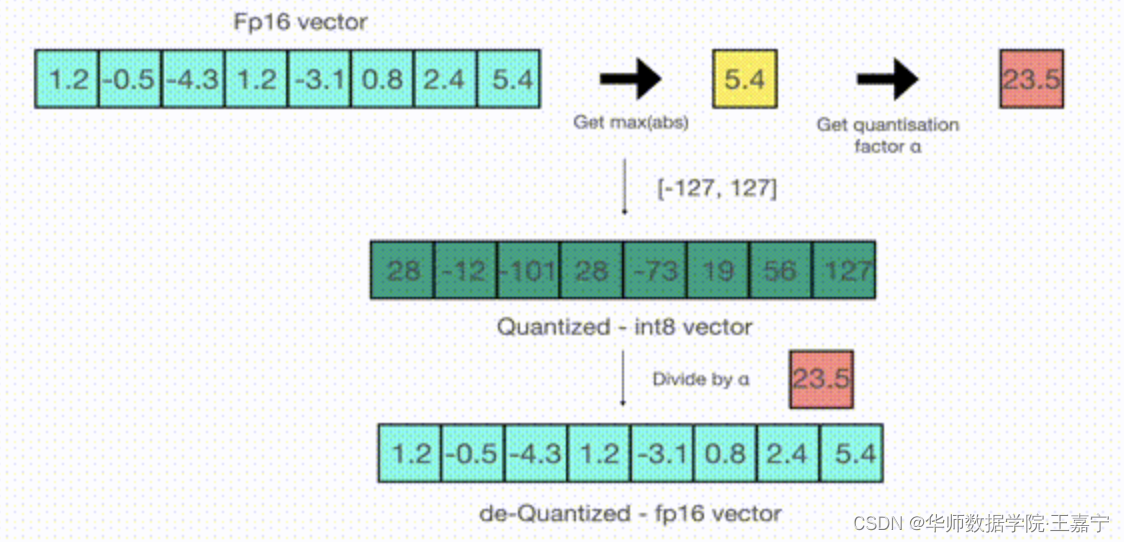
给定一个数组,首先找到该数组中的最大值5.4,然后计算127/5.4=23.5,因此量化因子则为23.5(相当于当前浮点数中最大值放大至-127~127区间内的最大值)。数组中的数乘以量化因子得到的值进行四舍五入估计,即可得到整型数组。 解码时,则将整型数除以量化因子即可。由于期间进行了四舍五入估计,因此量化时会有损失。 
(2)基于threshold的量化(量化裁剪) 在浮点数范围内,设置两个阈值,记作 l l l和 u u u( l < u l |
【本文地址】
今日新闻 |
推荐新闻 |